ArrayList、LinkedList的区别是什么
- ArrayList是基于数组实现的,而LinkedList是基于链表实现的。
- ArrayList支持在任意位置访问,时间复杂度为O(1),但是在随机插入的时候需要移动元素,时间复杂度为O(n)只有在数组末尾插入或删除元素的时间复杂度为O(1),LinkedList支持在任意位置插入删除和修改、删除,它只需要修改前后节点的指针即可,时间复杂度为O(1),但是无法支持随机访问,需要从头结点指针来遍历。
ArrayList、LinkedList是线程安全的吗
两者都不是,这还是回到了上一个问题的答案,因为ArrayList中维护了一个数组,在并发的情况下就是多线程同时去操作一个数组那么很有可能会出现数据不一致问题,LinkedList内部是一个双向链表,每个节点都有一个头尾指针,同样在并发环境中会出现线程安全问题。
如何创建一个线程安全的集合
在Java中创建一个线程安全的集合可以通过以下几种方法实现:
-
使用
Collections.synchronizedList()方法-
Collections.synchronizedList()方法可以将一个普通的List(如ArrayList或LinkedList)包装成线程安全的列表。这个方法会在列表的所有操作上添加同步锁,确保线程安全。 -
示例代码:
import java.util.ArrayList; import java.util.Collections; import java.util.List; public class ThreadSafeListExample { public static void main(String[] args) { ListsynchronizedList = Collections.synchronizedList(new ArrayList<>()); // 添加元素 synchronizedList.add("element1"); synchronizedList.add("element2"); // 访问元素 String element = synchronizedList.get(0); System.out.println(element); } } -
这种方法简单易用,但可能会影响性能,因为所有操作都会被同步。
-
-
使用
CopyOnWriteArrayList-
CopyOnWriteArrayList是java.util.concurrent包中的一个线程安全的List实现。它在写操作时创建底层数组的新副本,确保线程安全,适用于读多写少的场景。 -
示例代码:
import java.util.List; import java.util.concurrent.CopyOnWriteArrayList; public class CopyOnWriteArrayListExample { public static void main(String[] args) { ListcopyOnWriteArrayList = new CopyOnWriteArrayList<>(); // 添加元素 copyOnWriteArrayList.add("element1"); copyOnWriteArrayList.add("element2"); // 访问元素 String element = copyOnWriteArrayList.get(0); System.out.println(element); } } -
这种方法在写操作时会有额外的开销,但在读操作时性能较好。
-
-
使用
Collections.synchronizedSet()和Collections.synchronizedMap()-
类似地,
Collections类还提供了synchronizedSet()和synchronizedMap()方法,可以将Set和Map包装成线程安全的集合。 -
示例代码:
import java.util.Collections; import java.util.HashSet; import java.util.Map; import java.util.Set; import java.util.HashMap; public class ThreadSafeSetAndMapExample { public static void main(String[] args) { SetsynchronizedSet = Collections.synchronizedSet(new HashSet<>()); Map
-
-
使用
java.util.concurrent包中的集合类-
java.util.concurrent包中提供了多种线程安全的集合类,如ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentSkipListSet等。这些集合类在设计上考虑了并发性能,通常比使用Collections.synchronizedXXX()方法更高效。 -
示例代码:
import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentLinkedQueue; import java.util.concurrent.ConcurrentSkipListSet; public class ConcurrentCollectionsExample { public static void main(String[] args) { ConcurrentHashMapconcurrentLinkedQueue = new ConcurrentLinkedQueue<>(); ConcurrentSkipListSet concurrentSkipListSet = new ConcurrentSkipListSet<>(); // 添加元素 concurrentHashMap.put("key1", "value1"); concurrentLinkedQueue.add("element1"); concurrentSkipListSet.add("element1"); // 访问元素 String mapValue = concurrentHashMap.get("key1"); String queueElement = concurrentLinkedQueue.poll(); String setElement = concurrentSkipListSet.first(); System.out.println(mapValue); System.out.println(queueElement); System.out.println(setElement); } }
-
HashMap原理
HashMap是基于数组加+链表/红黑树的结构实现的
HashMap确实是基于数组和链表(或红黑树)的结构实现的。数组的每个元素称为“桶”(Bucket),每个桶可以存储一个链表(或红黑树)的头节点,通过对key的哈希运算的得到数组的索引位置即存储在哪个桶中,如果桶中为空则直接插入,如果不为空会对key进行比较,不相同会在链表末尾进行插入,相同的话则会覆盖原有的值,之后会对链表元素进行判断,长度大于阈值(默认是8)的话会转变成红黑树,同样红黑树中如果元素小于阈值(6)会退化成链表。HashMap的负载因子(Load Factor)默认为0.75。当HashMap中的元素数量超过负载因子乘以容量时,会触发扩容操作。
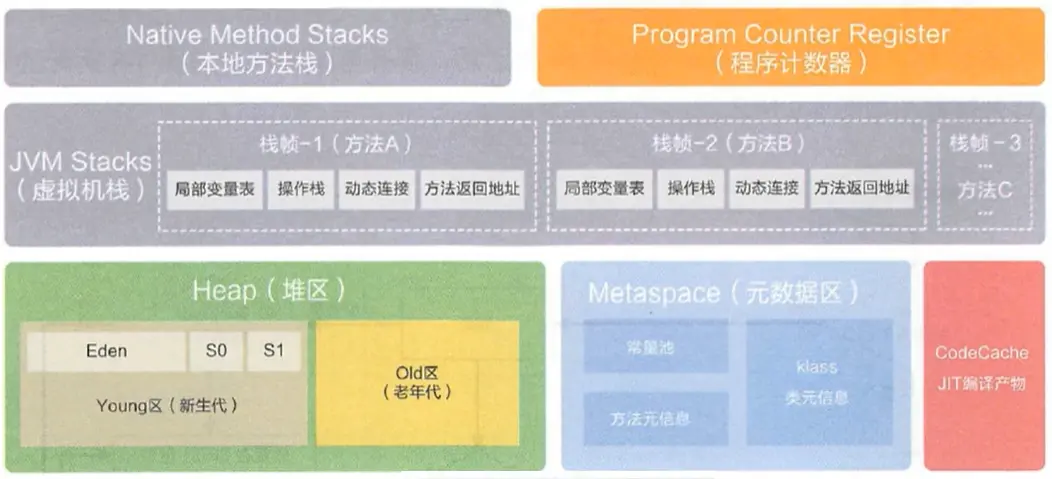
JVM内存模型
主要分成这几块
- 方法区(永久代/元空间):类型信息、静态变量、常量、即时编译后的产物
- 堆:对象和数组
- 虚拟机栈:存放的是jvm中一次次的方法调用
- 程序计数器:存放的是下一条指令的地址
- 本地方法栈:存放的是本地方法的调用
JVM垃圾回收算法
这里问了所有的垃圾回收算法,我直接放笔记的链接了。
G1垃圾回收器
同样放链接了。