全程没问过很多Java上的东西,都是MySQL上的。😔
B树和B+树
B树
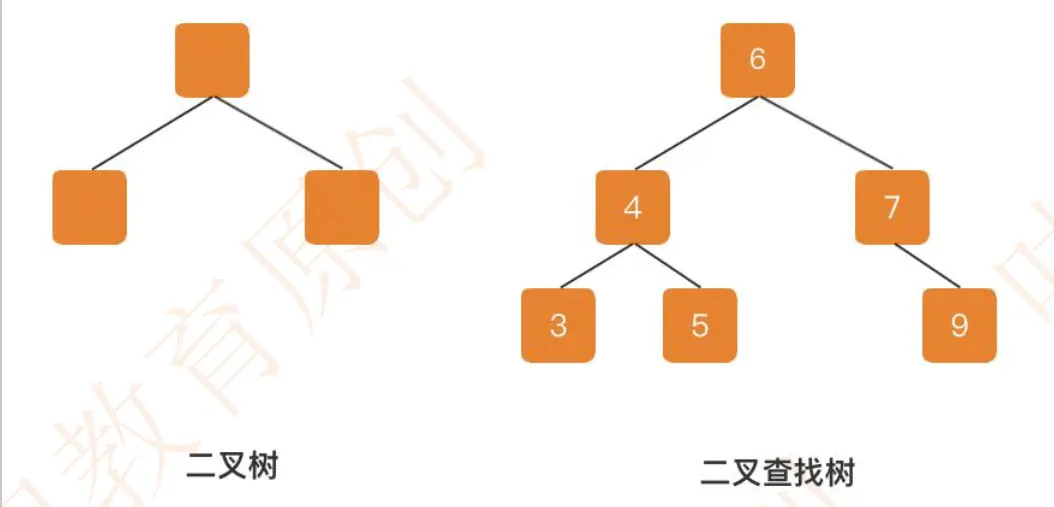
B 树是一种多路平衡查找树,为了更形象的理解,(我们来看这张图)。二叉树,每个节点支持两个分支的树结构,相比于单向链表,多了一个分支。
二叉查找树,在二叉树的基础上增加了一个规则,左子树的所有节点的值都小于它的根节点,右子树的所有子节点都大于它的根节点
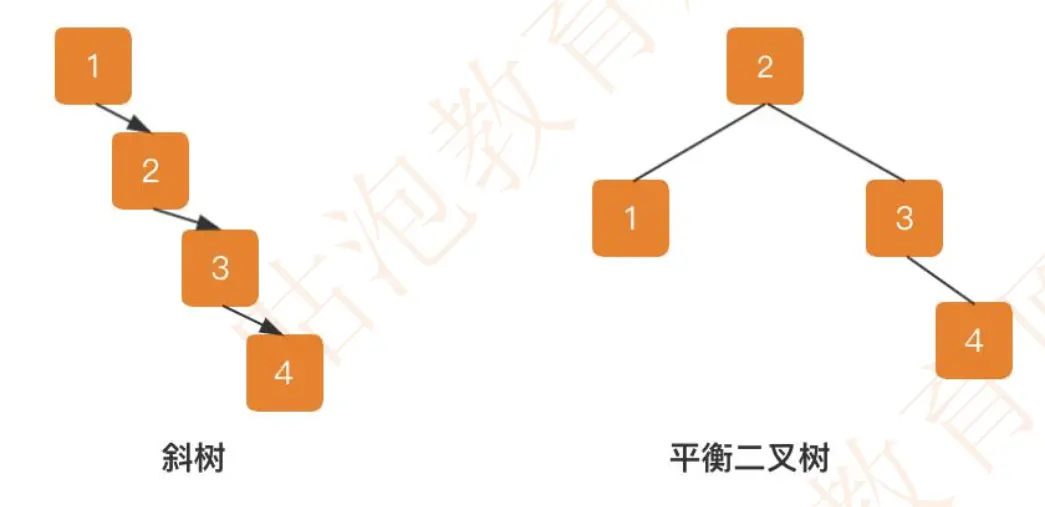
二叉查找树会出现斜树问题(如下图),导致时间复杂度增加,因此又引入了一种平衡二叉树,它具有二叉查找树的所有特点,同时增加了一个规则:”它的左右两个子树的高度差的绝对值不超过 1“。平衡二叉树会采用左旋、右旋的方式来实现平衡。
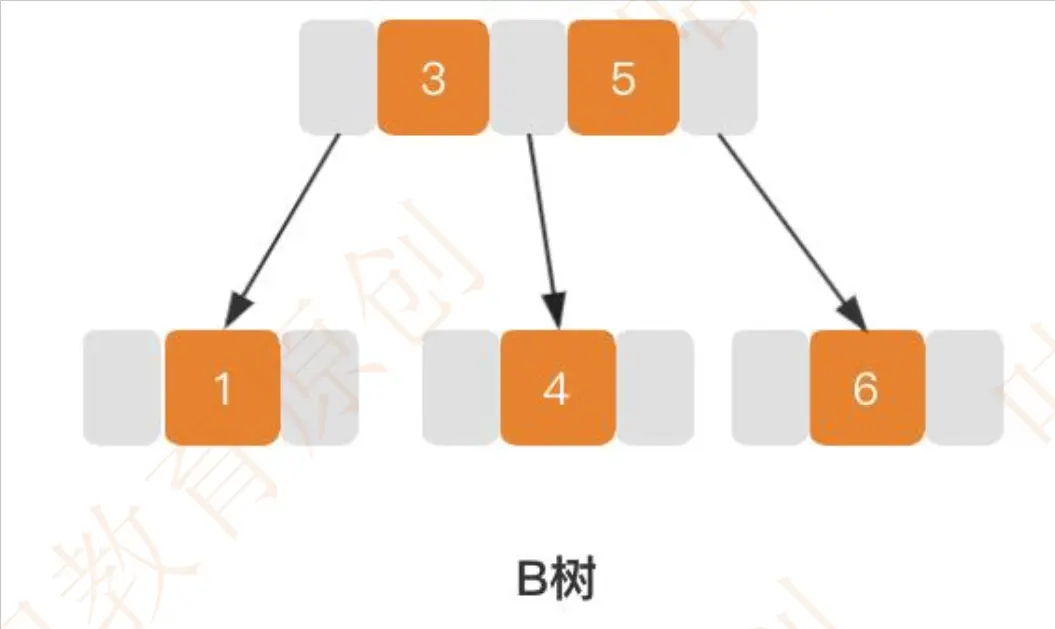
而 B 树是一种多路平衡查找树,它满足平衡二叉树的规则,但是它可以有多个子树,子树的数量取决于关键字的数量,比如下图中根节点有两个关键字 3 和 5,那么它能够拥有的子路数量=关键字数+1。
因此从这个特征来看,在存储同样数据量的情况下,平衡二叉树的高度要大于 B 树。
B+树
B+树,其实是在 B 树的基础上做的增强,最大的区别有两个:
-
B 树的数据存储在每个节点上,而 B+树中的数据是存储在叶子节点,并且通过链表的方式把叶子节点中的数据进行连接。
-
B+树的子路数量等于关键字数
这个是 B 树的存储结构,从 B 树上可以看到每个节点会存储数据。
这个是 B+树,B+树的所有数据是存储在叶子节点,并且叶子节点的数据是用双向链表关联的。
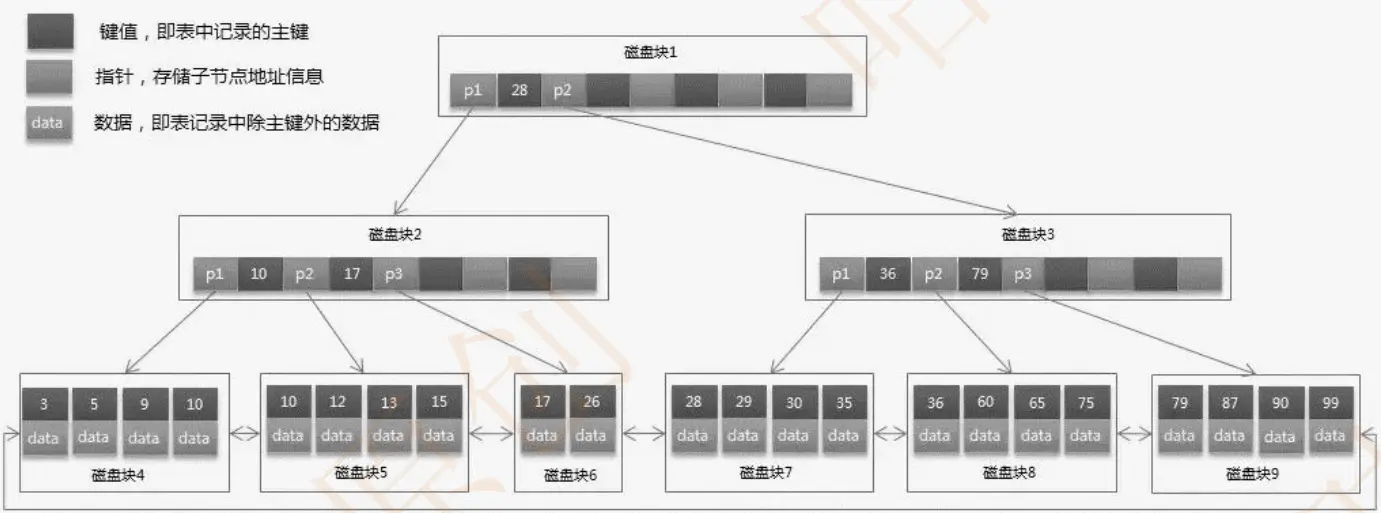
B 树和 B+树,一般都是应用在文件系统和数据库系统中,用来减少磁盘 IO 带来的性能损耗。
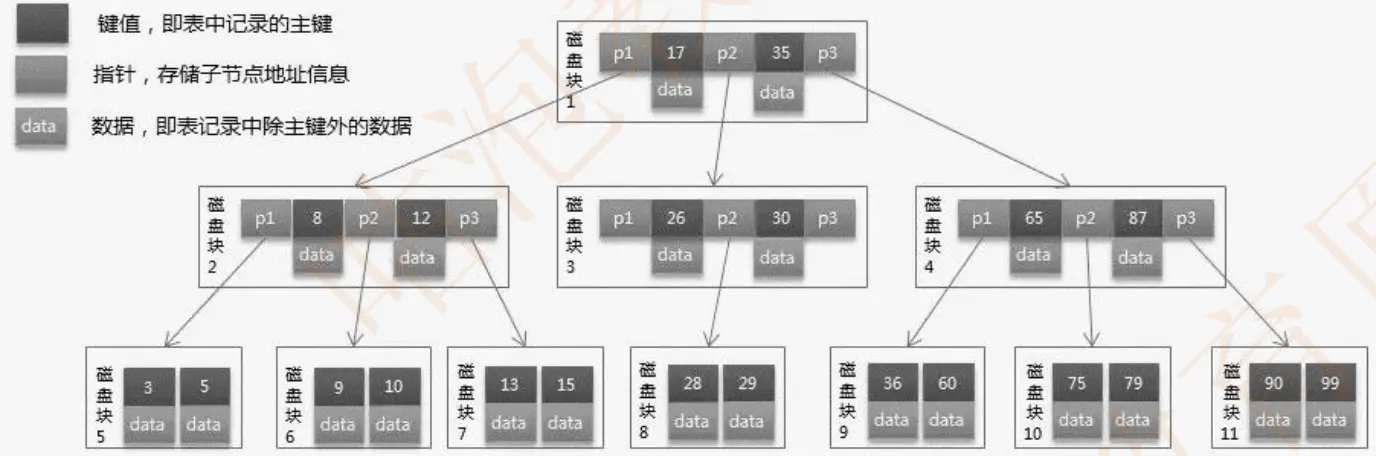
以 Mysql 中的 InnoDB 为例,当我们通过 select 语句去查询一条数据时,InnoDB 需要从磁盘上去读取数据,这个过程会涉及到磁盘 IO 以及磁盘的随机 IO(如图所示)我们知道磁盘 IO 的性能是特别低的,特别是随机磁盘 IO。
因为,磁盘 IO 的工作原理是,首先系统会把数据逻辑地址传给磁盘,磁盘控制电路按照寻址逻辑把逻辑地址翻译成物理地址,也就是确定要读取的数据在哪个磁道,哪个扇区。
为了读取这个扇区的数据,需要把磁头放在这个扇区的上面,为了实现这一个点,磁盘会不断旋转,把目标扇区旋转到磁头下面,使得磁头找到对应的磁道,这里涉及到寻道事件以及旋转时间。
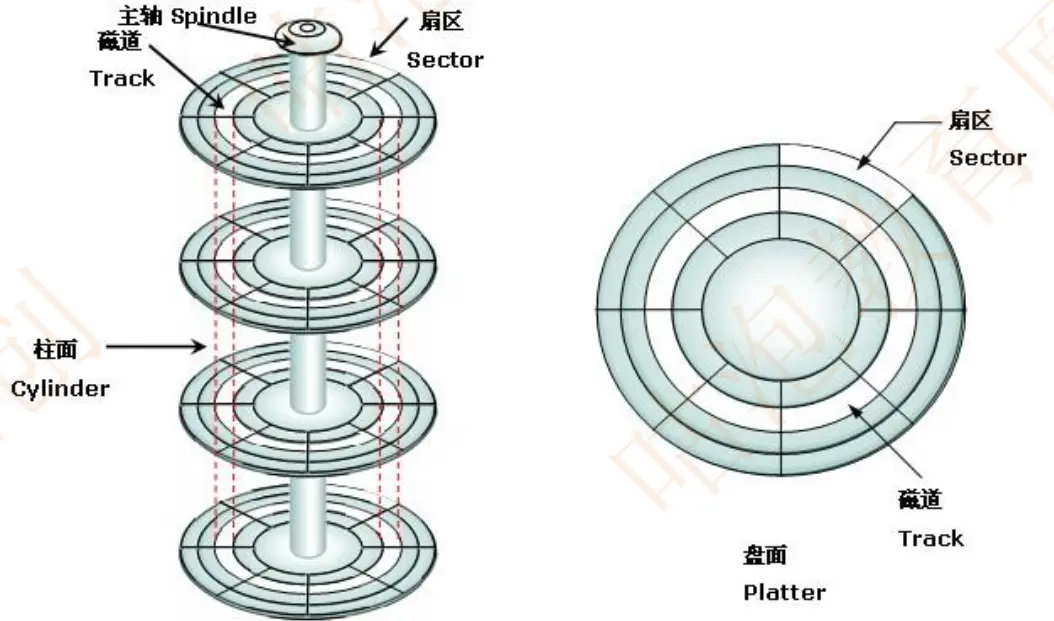
很明显,磁盘 IO 这个过程的性能开销是非常大的,特别是查询的数据量比较多的情况下。
所以在 InnoDB 中,干脆对存储在磁盘块上的数据建立一个索引,然后把索引数据以及索引列对应的磁盘地址,以 B+树的方式来存储。
如图所示,当我们需要查询目标数据的时候,根据索引从 B+树中查找目标数据即可,由于 B+树分路较多,所以只需要较少次数的磁盘 IO 就能查找到。
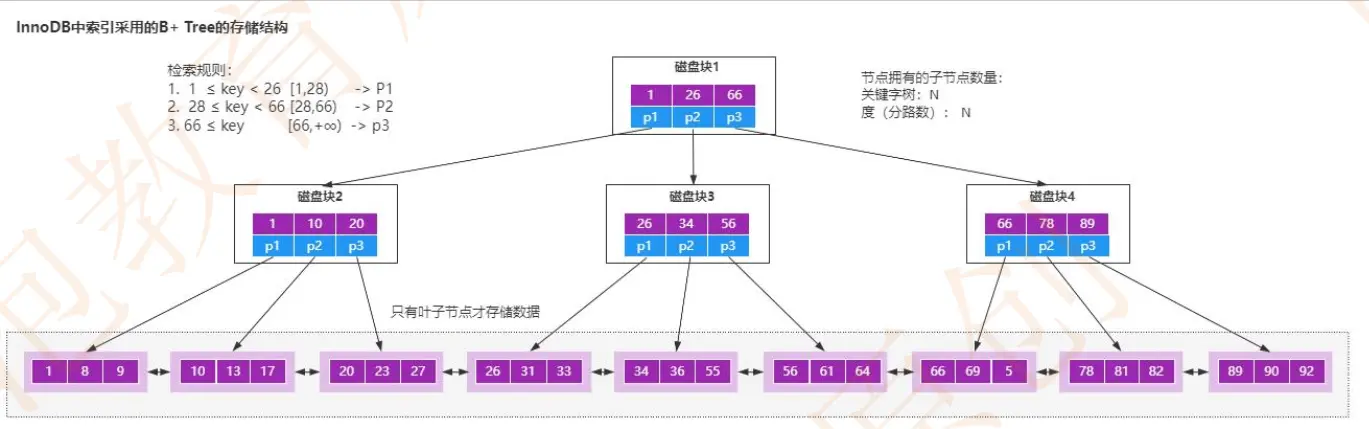
为什么用 B 树或者 B+树来做索引结构?
原因是 AVL 树的高度要比 B 树的高度要高,而高度就意味着磁盘 IO 的数量。所以为了减少磁盘 IO 的次数,文件系统或者数据库才会采用 B 树或者 B+树。
MySQL如何防止死锁,在java代码上如何进行规避
MySQL死锁的发生
死锁是指两个或多个事务相互等待对方释放资源,导致所有事务都无法继续执行的状态。在MySQL中,死锁通常发生在以下情况:
- 交叉锁请求:两个事务分别持有对方需要的锁,并且都在等待对方释放锁。
- 锁升级:一个事务从较低级别的锁(如行锁)升级到较高级别的锁(如表锁),而另一个事务持有该表的锁。
- 锁超时:一个事务等待锁的时间超过了设定的超时时间,导致锁请求失败。
如何防止死锁
-
事务隔离级别:
- 使用较低的事务隔离级别(如
READ COMMITTED)可以减少锁的持有时间,从而降低死锁的可能性。 - 但要注意,较低的隔离级别可能会导致数据一致性问题。
- 使用较低的事务隔离级别(如
-
事务顺序:
- 确保所有事务以相同的顺序访问资源。例如,如果多个事务都需要锁定表A和表B,那么所有事务都应该先锁定表A,再锁定表B。
-
事务超时:
- 设置事务的超时时间,如果事务等待锁的时间超过了超时时间,则自动回滚事务。
-
锁粒度:
- 尽量使用较小的锁粒度(如行锁),而不是较大的锁粒度(如表锁),以减少锁冲突的可能性。
-
避免长事务:
- 尽量缩短事务的执行时间,减少锁的持有时间。
在Java代码上如何进行规避
-
事务管理:
-
使用Spring框架的事务管理功能,确保事务的隔离级别、传播行为和超时时间设置合理。
-
例如,使用
@Transactional注解来管理事务:@Transactional(isolation = Isolation.READ_COMMITTED, timeout = 30) public void performTransaction() { // 事务逻辑 }
-
-
资源顺序:
- 在代码中确保所有事务以相同的顺序访问数据库资源。例如,如果多个事务都需要更新表A和表B,确保所有事务都先更新表A,再更新表B。
-
锁超时处理:
-
在代码中捕获锁超时异常(如
LockTimeoutException),并进行相应的处理,例如回滚事务或重试。 -
例如:
try { performTransaction(); } catch (LockTimeoutException e) { // 处理锁超时异常 TransactionAspectSupport.currentTransactionStatus().setRollbackOnly(); }
-
-
重试机制:
-
对于可能发生死锁的场景,可以实现重试机制。如果检测到死锁,可以等待一段时间后重试事务。
-
例如:
int retryCount = 3; for (int i = 0; i < retryCount; i++) { try { performTransaction(); break; } catch (DeadlockException e) { if (i == retryCount - 1) { throw e; } Thread.sleep(1000); // 等待1秒后重试 } }
-
-
监控和日志:
- 监控数据库的死锁情况,并记录死锁日志。通过分析日志,可以找出死锁的根本原因,并进行优化。
自身优化
在MySQL的Server引擎中,为了防止死锁,做了以下几方面的设计和优化:
1. 死锁检测
MySQL内置了死锁检测机制,通过定期检查事务之间的依赖关系来识别死锁。当检测到死锁时,MySQL会选择一个事务作为“牺牲品”,并回滚该事务,从而打破死锁状态。
- 死锁检测算法:MySQL使用了一种称为“等待图”(Wait-For Graph)的算法来检测死锁。等待图是一个有向图,其中节点表示事务,边表示事务之间的等待关系。如果图中存在环路,则表示发生了死锁。
2. 自动回滚
当死锁被检测到时,MySQL会自动选择一个事务进行回滚,通常是选择代价最小的事务(即回滚该事务所需的工作量最小)。被回滚的事务会收到一个ER_LOCK_DEADLOCK错误。
- 回滚策略:MySQL会选择一个事务进行回滚,而不是简单地终止所有事务。这样可以最小化对系统的影响。
3. 锁超时
MySQL允许为锁请求设置超时时间。如果一个事务在等待锁的时间超过了设定的超时时间,MySQL会自动放弃该锁请求,并回滚事务。
-
innodb_lock_wait_timeout:这是一个全局变量,用于设置锁等待的超时时间(以秒为单位)。默认值通常是50秒。
SET innodb_lock_wait_timeout = 30; -- 设置锁等待超时时间为30秒
4. 事务隔离级别
MySQL支持多种事务隔离级别,不同的隔离级别对锁的使用有不同的影响。较低的隔离级别(如READ COMMITTED)可以减少锁的持有时间,从而降低死锁的可能性。
-
隔离级别设置:可以通过SQL语句或配置文件设置事务隔离级别。
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
5. 锁粒度控制
MySQL的InnoDB存储引擎支持多种锁粒度,包括行锁、页锁和表锁。通过合理选择锁粒度,可以减少锁冲突的可能性。
- 行锁:InnoDB默认使用行锁,行锁的粒度较小,可以减少锁冲突。
- 表锁:在某些情况下,InnoDB会自动升级为表锁,但这通常是为了提高性能或避免死锁。
6. 事务顺序控制
虽然MySQL本身不直接控制事务的执行顺序,但通过合理的事务设计和应用程序逻辑,可以减少死锁的发生。例如,确保所有事务以相同的顺序访问资源。
7. 死锁日志记录
MySQL会记录死锁信息,包括死锁发生的时间、涉及的事务、锁的类型等。这些日志信息可以帮助DBA分析死锁的原因,并进行优化。
-
死锁日志:死锁信息通常记录在MySQL的错误日志中,可以通过以下命令查看:
SHOW ENGINE INNODB STATUS;
如何防止行锁变成表锁
行锁和表锁的发生
在MySQL的InnoDB存储引擎中,锁的粒度可以分为行锁和表锁。行锁和表锁的发生主要与以下因素有关:
1. 行锁
行锁(Row-Level Locking)是InnoDB的默认锁机制。行锁只锁定特定的行,而不是整个表。行锁的粒度较小,可以提高并发性能,但也会增加锁管理的复杂性。
- 行锁的发生:
- 当一个事务对某一行进行修改(如
UPDATE、DELETE)时,InnoDB会自动对该行加锁。 - 如果事务使用了
SELECT ... FOR UPDATE或SELECT ... LOCK IN SHARE MODE语句,InnoDB也会对查询到的行加锁。
- 当一个事务对某一行进行修改(如
2. 表锁
表锁(Table-Level Locking)是锁定整个表的锁机制。表锁的粒度较大,会阻塞其他事务对整个表的访问,因此并发性能较差。
- 表锁的发生:
- 显式表锁:使用
LOCK TABLES语句可以显式地对表加锁。 - 隐式表锁:在某些情况下,InnoDB会自动将行锁升级为表锁,例如:
- 当一个事务对某个表进行全表扫描时,InnoDB可能会将行锁升级为表锁,以提高性能。
- 当一个事务对某个表进行DDL操作(如
ALTER TABLE)时,InnoDB会自动对该表加表锁。
- 显式表锁:使用
如何防止行锁变成表锁
为了避免行锁升级为表锁,可以采取以下措施:
1. 优化查询
-
避免全表扫描:尽量使用索引进行查询,避免全表扫描。全表扫描会导致InnoDB将行锁升级为表锁。
- 例如,使用
WHERE子句来限制查询的范围:
SELECT * FROM my_table WHERE id = 123; -- 使用索引 - 例如,使用
-
分页查询:对于大数据量的查询,使用分页查询(如
LIMIT)来减少锁定的行数。- 例如:
SELECT * FROM my_table ORDER BY id LIMIT 100;
2. 减少锁的持有时间
-
缩短事务时间:尽量缩短事务的执行时间,减少锁的持有时间。
- 例如,将长时间的操作拆分为多个小事务:
START TRANSACTION; UPDATE my_table SET column1 = 'value1' WHERE id = 123; COMMIT; -
批量操作:对于批量操作,尽量减少单个事务的操作量。
- 例如,将批量插入操作拆分为多个小批次:
START TRANSACTION; INSERT INTO my_table (column1, column2) VALUES ('value1', 'value2'); COMMIT;
3. 使用较低的隔离级别
-
降低隔离级别:使用较低的事务隔离级别(如
READ COMMITTED)可以减少锁的持有时间,从而降低行锁升级为表锁的可能性。- 例如:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
4. 合理使用锁
-
显式锁:在必要时使用显式锁(如
SELECT ... FOR UPDATE),而不是隐式锁。- 例如:
SELECT * FROM my_table WHERE id = 123 FOR UPDATE; -
避免不必要的锁:尽量避免对不需要锁定的行进行锁定操作。
- 例如,对于只读操作,使用
SELECT ... LOCK IN SHARE MODE而不是SELECT ... FOR UPDATE。
- 例如,对于只读操作,使用
5. 监控和优化
-
监控锁情况:使用MySQL的监控工具(如
SHOW ENGINE INNODB STATUS)来监控锁的使用情况,及时发现和解决锁冲突问题。- 例如:
SHOW ENGINE INNODB STATUS; -
优化表结构:合理设计表结构,使用适当的索引,减少锁冲突的可能性。
- 例如,为频繁更新的列创建索引:
CREATE INDEX idx_column1 ON my_table(column1);
MySQL减少锁等待的方式
在MySQL中,减少锁等待是提高数据库并发性能的关键。锁等待是指一个事务在等待另一个事务释放锁资源时所经历的时间。通过以下几种方式,可以有效减少锁等待,提高系统的并发性能:
1. 优化查询
1.1 使用索引
-
索引优化:确保查询中使用的列上有适当的索引。索引可以显著减少查询的执行时间,从而减少锁的持有时间。
- 例如,为经常查询的列创建索引:
CREATE INDEX idx_column1 ON my_table(column1); -
覆盖索引:使用覆盖索引(Covering Index),即索引包含了查询所需的所有列,从而避免回表操作,减少锁的持有时间。
- 例如:
SELECT column1, column2 FROM my_table WHERE column1 = 'value';
1.2 避免全表扫描
-
避免全表扫描:全表扫描会导致InnoDB将行锁升级为表锁,从而增加锁等待时间。尽量使用
WHERE子句来限制查询的范围。- 例如:
SELECT * FROM my_table WHERE id = 123; -- 使用索引
2. 减少锁的持有时间
2.1 缩短事务时间
-
事务拆分:尽量将长时间的事务拆分为多个小事务,减少锁的持有时间。
- 例如:
START TRANSACTION; UPDATE my_table SET column1 = 'value1' WHERE id = 123; COMMIT; -
批量操作:对于批量操作,尽量减少单个事务的操作量。
- 例如:
START TRANSACTION; INSERT INTO my_table (column1, column2) VALUES ('value1', 'value2'); COMMIT;
2.2 使用较低的隔离级别
-
降低隔离级别:使用较低的事务隔离级别(如
READ COMMITTED)可以减少锁的持有时间,从而降低锁等待的可能性。- 例如:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
3. 合理使用锁
3.1 显式锁
-
显式锁:在必要时使用显式锁(如
SELECT ... FOR UPDATE),而不是隐式锁。- 例如:
SELECT * FROM my_table WHERE id = 123 FOR UPDATE; -
避免不必要的锁:尽量避免对不需要锁定的行进行锁定操作。
- 例如,对于只读操作,使用
SELECT ... LOCK IN SHARE MODE而不是SELECT ... FOR UPDATE。
- 例如,对于只读操作,使用
3.2 锁超时设置
-
锁超时:设置锁等待的超时时间,如果一个事务在等待锁的时间超过了设定的超时时间,则自动放弃该锁请求,并回滚事务。
- 例如:
SET innodb_lock_wait_timeout = 30; -- 设置锁等待超时时间为30秒
4. 监控和优化
4.1 监控锁情况
-
监控工具:使用MySQL的监控工具(如
SHOW ENGINE INNODB STATUS)来监控锁的使用情况,及时发现和解决锁冲突问题。- 例如:
SHOW ENGINE INNODB STATUS; -
死锁日志:记录死锁信息,分析死锁的根本原因,并进行优化。
- 例如:
SHOW ENGINE INNODB STATUS;
4.2 优化表结构
-
合理设计表结构:合理设计表结构,使用适当的索引,减少锁冲突的可能性。
- 例如,为频繁更新的列创建索引:
CREATE INDEX idx_column1 ON my_table(column1);
5. 并发控制
5.1 乐观锁
-
乐观锁:使用乐观锁机制,假设数据在大多数情况下不会发生冲突,从而减少锁的使用。
- 例如,使用版本号或时间戳来实现乐观锁:
UPDATE my_table SET column1 = 'value1', version = version + 1 WHERE id = 123 AND version = 1;
5.2 悲观锁
-
悲观锁:在必要时使用悲观锁机制,确保数据的一致性。
- 例如,使用
SELECT ... FOR UPDATE来锁定行:
SELECT * FROM my_table WHERE id = 123 FOR UPDATE; - 例如,使用